

We have now understood how to assign unique identities to every user through public and private keys and conduct transactions between these entities through the use of the UTXO, or Unspent Transaction Output, model.
So naturally, the next question to ask is: How do we keep track of the history of transactions? After all a user’s current balance can be described as a number of transactions, summing to the current amount, and if we don’t know what transactions have happened in the past, we can’t determine what’s valid in the future.
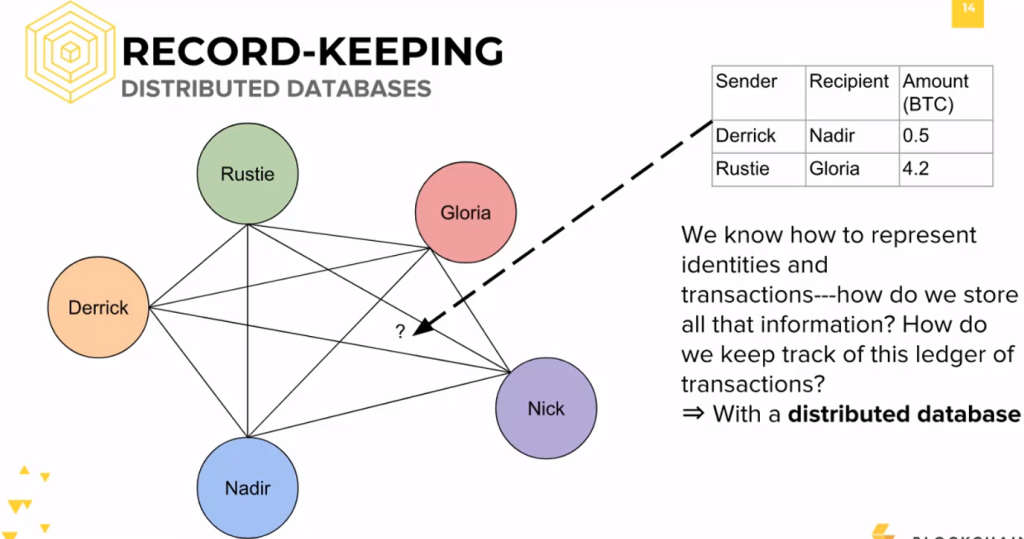
Consider the diagram on the left side.
Let this represent our network, which includes 5 entities.
Each of these circles represents an identity: me (Rustie) in green on top, Gloria in red on the top right, Nick in purple on the bottom right, Nadir in blue on the bottom left, and Derrick in orange on the top left.
We are all connected to each other on this network, as is apparent by the straight edges connecting each circle.
For simplicity’s sake, I’ve replaced all public keys with names.
I’ve also replaced the UTXO model with a basic table on the top right hand side of the screen.
We need to store the history of transactions for obvious reasons: to know who owns what in the present, and to use this history to confirm the validity of future transactions.
To save this information, we need some form of database.
A database is a store of information, and there are many types and implementations of databases.
To understand which type of database we need to use in Bitcoin, let’s recall again the requirements of the Bitcoin protocol: we want no central entity in control of the information in the network, and we want a way for anyone to be able to read and write to the history of transactions.
Hence, we want to use a distributed database: as its name entails, information stored in a distributed manner, meaning that the information is not stored by one entity or only in one location.
Because Bitcoin aims to be decentralized, we want to use exactly that.
So what does this distributed database look like, and where exactly is it stored? There’s no central entity to hold on to our information, so the closest thing is having a chosen set of entities hold onto this history.
If we assigned several entities in the network the responsibility of maintaining and sharing our ledger of transactions, we are still seeing some parts of centralization sneak their way into our protocol because we would have to trust the maintainers of this distributed database, going against Bitcoin’s aim to be a trustless system.
We must find another way.
Instead of having any selected maintainers, let’s make a simple and straightforward choice: we have everyone keep a copy of the ledger.
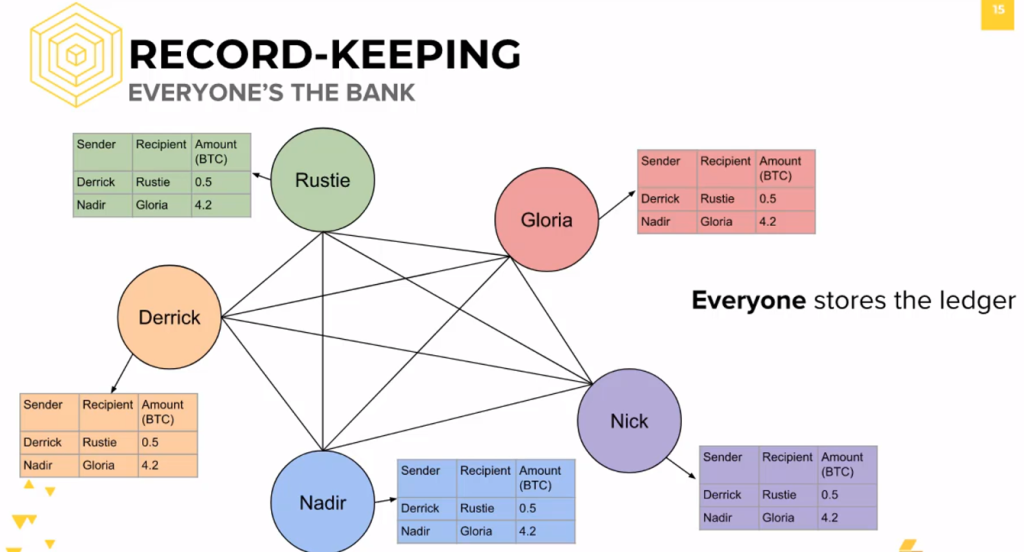
We make everyone the bank.
To get as far as possible from centralization, every individual entity in Bitcoin should be equal.
If every person stores the ledger, then every person has just as much right and legitimacy as the next person to vote on the validity of transactions.
Every person has control of their own data, and no person can decide for anyone else.
There’s no one person to bribe, no one person to hack, no one person to cheat in order to alter the database.
This is the maximum state of individual independence possible for maintaining this history of transactions.
We know that we want each person to store the ledger, but what should the database actually look like? What data structures hold the transaction history? We might naively decide to store every transaction individually, but for a network that may be dealing with many transactions per second, updating the database for every received transaction will be costly, especially since this update would have to be delivered to everyone in the network.
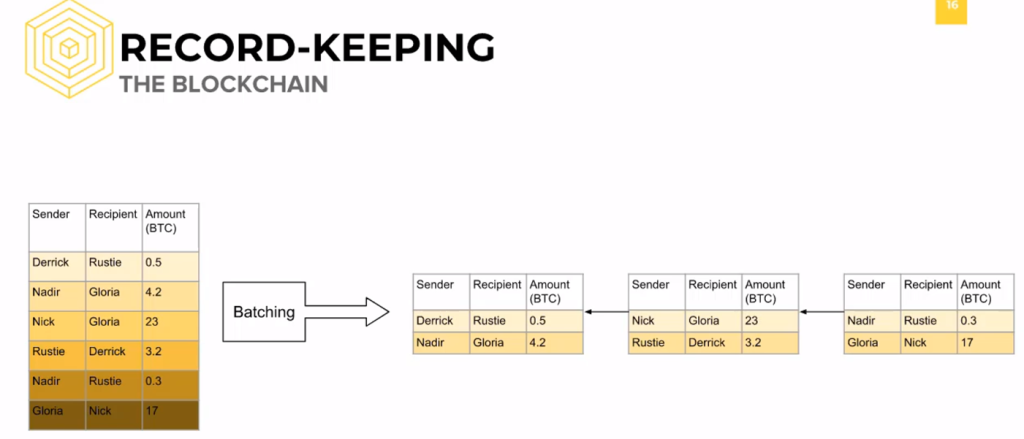
Everyone maintains their own ledger after all, and once a change is made for one entity, it must propagate throughout the entire network.
So, how do we store our ledger efficiently? [The Blockchain] Every update to the distributed database, the Bitcoin ledger, is a batch of transactions grouped into what are called blocks.
Every block is built off, or chained to, a previous block.
Altogether, this forms a magical data structure known as a “blockchain.” By grouping data into blocks, we do not have to strain the network as a result of updating every ledger after every transaction.
With a blockchain, only every block, which may contain thousands of transactions, needs to be appended to the blockchain.
In this way, blockchains efficiently keep track of not only the transactions in any given update but also give the database discrete states.
Every block is an update, and a chain of blocks represents a history.
This process is is helpful for identifying discrepancies between two different versions of the database, since it’s much more clear what happened in the ledger at any given time than if every transaction were individually processed.
Every block contains information about the previous block, as every block is built off the previous one.
If any block is mutated, intentionally or not, information within this block and all future blocks will change.
This makes the blockchain tamper-evident, as tampering with a transaction from the past would invalidate any future blocks linking back to it.
To reiterate, this design choice is both to reduce the strain of storing individual transactions and to facilitate consistency between all members of the Bitcoin network.
Of course, the next question is, “How does everyone come to agreement on the next block?” We will go over this in the next video segment on consensus.